Nearly a book review: Situational Awareness, by Leopold Aschenbrenner.
“Situational Awareness” offers an insightful analysis of our proximity to a critical threshold in AI capabilities. His background in machine learning and economics lends credibility to his predictions.
The paper left me with a rather different set of confusions than I started with.
Rapid Progress
His extrapolation of recent trends culminates in the onset of an intelligence explosion: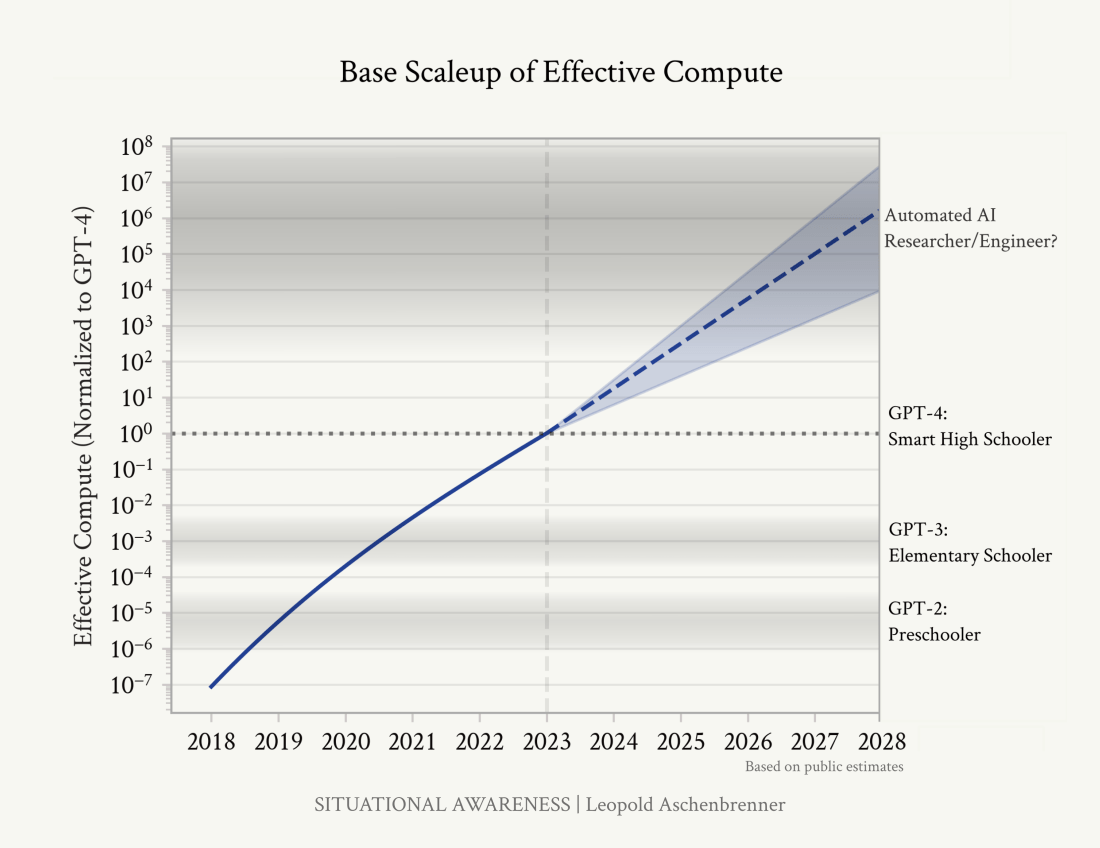
His assessment of GPT-4 as equivalent to a smart high schooler depends significantly on the metrics used. For long-term planning abilities, this estimate may be overstated by about five orders of magnitude. However, by other measures, his assessment seems somewhat reasonable.
Initially, I expected the timeline for automated AI researchers to be slightly longer than Aschenbrenner’s 2028 prediction, due to limitations in their long-term planning abilities. However, upon closer examination, I found his argument less dependent on overcoming such weaknesses than I first thought. So I’m not going to bet very much against his claim here.
One neat way to think about this is that the current trend of AI progress is proceeding at roughly 3x the pace of child development. Your 3x-speed-child just graduated high school; it’ll be taking your job before you know it!
While a 3x pace seems somewhat high to me – I’d estimate closer to a 1:1 ratio – his overall forecast for 2028 may not be far off, considering that he may be overestimating the gap between a smart high schooler and an assistant AI researcher.
Aschenbrenner has a section on the “data wall” that seems a bit suspicious. He expects increasing divergence in the results of various lab’s progress due to need for increasingly important algorithmic insights to get around the problem.
While AI training is indeed data-dependent, and much of the easily accessible data has been used, I believe data scarcity may be less problematic than Aschenbrenner suggests. Rather than a “wall,” I see it as having picked the low-hanging fruit. Untapped sources of useful data likely exist, with the primary challenge being the cost of acquisition. I’m reluctant to give examples, just in case there are players who haven’t figured it out yet. I suspect the most advanced labs will be bottlenecked more by compute than by data.
There will be modest differences in how quickly labs throw lots of money at gathering data. If labs’ progress diverges much, it will likely be due to something else (see the next section, on unhobbling).
Aschenbrenner decomposes the drivers of progress into three factors: physical compute, algorithmic efficiencies, and unhobbling.
Physical compute is expected to increase nearly four-fold annually until around 2030, with subsequent acceleration or deceleration depending on whether AI has a dramatic transformative impact on global economic growth.
Algorithmic efficiencies, focusing on low-level optimizations, have been surprisingly impactful, doubling effective compute roughly every eight months. I’m guessing this includes minor improvements to matrix multiply algorithms, or figuring out that some operations can be skipped because they don’t affect the end result.
Or consider adaptive compute: Llama 3 still spends as much compute on predicting the “and” token as it does the answer to some complicated question, which seems clearly suboptimal.
The evidence here isn’t strong enough to establish a clear long-term trend. My intuition says that it’s partly due to a burst of improvements from 2019 to 2022, as researchers suddenly realized those improvements were ridiculously valuable, with diminishing returns potentially already slowing these effects.
Unhobbling

The concept of “unhobbling” suggests that current AIs possess latent human-level intelligence capabilities, hampered by clumsy usage. This potential is being unlocked through high-level algorithmic advances like chain of thought, expanded context windows, and scaffolding.
E.g.:
GPT-4 has the raw smarts to do a decent chunk of many people’s jobs, but it’s sort of like a smart new hire that just showed up 5 minutes ago
We’re still just beginning to figure out how to turn GPT-4 into a worker that has developed some expertise in a particular job.
His framing of high-level algorithmic progress as unhobbling of latent intelligence is somewhat unusual. Most discussions of AI seem to assume that existing AIs need to acquire some additional source of basic intelligence in order to function at near-human levels.
Is Aschenbrenner’s framing is better? He seems at least partly correct here. When performance is improved by simple tricks such as offering a chatbot a tip, it’s pretty clear there’s some hidden intelligence that hasn’t be fully exposed.
I’m unsure whether most high-level algorithmic progress is better described as unhobbling or as finding new sources of intelligence. The magnitude of such latent intelligence is hard to evaluate. For now, I’m alternating between the unhobbling model and the new sources of intelligence model.
Aschenbrenner estimates unhobbling to be as significant as the other two drivers. While evidence is inconclusive, it’s conceivable that unhobbling could become the primary driver of progress in the coming years. This uncertainty is makes me nervous.
By the end of this, I expect us to get something that looks a lot like a drop-in remote worker.
Intelligence Explosion
I’ve been somewhat reluctant to use the term intelligence explosion, because it has been associated with a model from Eliezer Yudkowsky that seems somewhat wrong.
Aschenbrenner’s description of an intelligence explosion aligns more closely with a Hansonian framing. It’s more compatible with my understanding of the emergence of human intelligence, and potentially even the Cambrian explosion.
His projection suggests AIs will take over much of AI research by late 2027.
We’d be able to run millions of copies (and soon at 10x+ human speed) of the automated AI researchers.
While millions of AI researcher copies is higher than what I expect, the overall analysis doesn’t hinge on this specific number.
Imagine 1000 automated AI researchers spending a month-equivalent checking your code and getting the exact experiment right before you press go. I’ve asked some AI lab colleagues about this and they agreed: you should pretty easily be able to save 3x-10x of compute on most projects merely if you could avoid frivolous bugs, get things right on the first try, and only run high value-of-information experiments.
This model posits that the explosion begins when the cognitive resources devoted to AI development increase at superhuman rates, not necessarily requiring AIs to perform all relevant tasks. Doing AI research requires some specialized brilliance, but doesn’t require researchers whose abilities are as general-purpose as humans.
The massive increase in labor could accelerate algorithmic progress by at least 10x – a change dramatic enough to warrant the term “explosion.”
I can believe that we’ll get a year of 10x algorithmic progress. I expect that after that year, progress will depend much more heavily on compute.
How much will that increase in intelligence enable faster production of compute? Aschenbrenner doesn’t tackle that question, and I’m fairly uncertain.
It seems ironic that Aschenbrenner has used Hansonian framing to update my beliefs modestly towards Eliezer’s prediction of a fast takeoff. Although most of the new evidence provided is about trends in algorithmic progress.
The prediction that LLM-based AI will trigger the explosion doesn’t mean that superintelligence will be an LLM:
The superintelligence we get by the end of it could be quite alien. We’ll have gone through a decade or more of ML advances during the intelligence explosion, meaning the architectures and training algorithms will be totally different (with potentially much riskier safety properties).
Superalignment
RLHF relies on humans being able to understand and supervise AI behavior, which fundamentally won’t scale to superhuman systems.

By default, it may well learn to lie, to commit fraud, to deceive, to hack, to seek power, and so on
The primary problem is that for whatever you want to instill the model (including ensuring very basic things, like “follow the law”!) we don’t yet know how to do that for the very powerful AI systems we are building very soon. … What’s more, I expect that within a small number of years, these AI systems will be integrated in many critical systems, including military systems (failure to do so would mean complete dominance by adversaries).
Aschenbrenner acknowledges significant concerns about safe AI development. However, his tone, particularly in his podcast with Dwarkesh, sounds very much the opposite of scared.
This seems more like fatalism than a well thought out plan. I suspect he finds it hard to imagine scenarios under which safety takes more than a year to develop with AI assistance, so he prays that that will be enough.
Or maybe he’s seen fear paralyze some leading AI safety advocates, and wants to err in the other direction?
Lock Down the Labs
Aschenbrenner anticipates that competition between the US and China will pressure AI labs to compromise safety.
in the next 12-24 months, we will develop the key algorithmic breakthroughs for AGI, and promptly leak them to the CCP
But the AI labs are developing the algorithmic secrets—the key technical breakthroughs, the blueprints so to speak—for the AGI right now (in particular, the RL/self-play/synthetic data/etc “next paradigm” after LLMs to get past the data wall). AGI-level security for algorithmic secrets is necessary years before AGI-level security for weights. These algorithmic breakthroughs will matter more than a 10x or 100x larger cluster in a few years
a healthy lead will be the necessary buffer that gives us margin to get AI safety right, too
the difference between a 1-2 year and 1-2 month lead will really matter for navigating the perils of superintelligence
He recommends military-level security to protect key algorithmic breakthroughs, arguing that this is the primary area where the US can outcompete China.
Such security would slow AI advances, partly by reducing communications within each AI lab, and partly by impairing the ability of AI labs to hire employees who might be blackmailed by the CCP. Presumably he thinks the slowdown is small compared to the difference in how fast the two countries can make algorithmic progress on their own. I’m disturbed that he’s not explicit about this. It’s not at all obvious that he’s correct here.
What about the current US lead in compute? Why won’t it be enough for the US to win a race?
China may outbuild the US.
The binding constraint on the largest training clusters won’t be chips, but industrial mobilization—perhaps most of all the 100GW of power for the trillion-dollar cluster. But if there’s one thing China can do better than the US it’s building stuff.
I can see how they might build more datacenters than the US. But what chips would they put into them? China now has little access to the best NVIDIA chips or ASML equipment. Those companies have proven hard for anyone to compete with. My impression is that even if China is on track to have twice as many datacenters, they’re going to be running at somewhat less than half the speed of US datacenters.
Aschenbrenner seems to think that China can make up with quantity for their lack of quality. That’s a complex topic. It looks like most experts think he’s wrong. But I see few signs of experts who are thinking more deeply than Aschenbrenner about this.
Can we see signs of a massive Chinese datacenter buildup now? My attempts at researching this yielded reports such as this predicting 3.54% annual growth in datacenter construction. That seems ridiculously low even if China decides that AI progress is slowing.
What about stocks of companies involved in the buildup? GDS Holdings and VNET Group seem to be the best available indicators of Chinese datacenter activity. Markets are very much not predicting a boom there. But I suppose the CCP could have serious plans that have been successfully kept secret so far.
My guess is that Aschenbrenner is wrong about Chinese ability to catch up to the US in compute by 2028, unless US regulation significantly restricts compute.
China might not have the same caution slowing it down that the US will
I don’t see how to predict which country will be more cautious. This seems like a crucial factor in determining which side we should prefer to lead. Shouldn’t we examine some real evidence? I don’t know what evidence Aschenbrenner is relying on, and my brief search for such evidence failed to turn up anything that I consider worth reporting here.
What happens when the free world’s progress is slowed by chip foundries being destroyed when China invades Taiwan? Aschenbrenner is aware that this is somewhat likely to happen this decade, but he says little about what it implies.
China will have some awareness of the possibility of an intelligence explosion. That might influence the timing of military action.
I fear that Aschenbrenner’s anti-CCP attitude will increase the risk of an all-out arms race.
Aschenbrenner’s approach here practically guarantees the kind of arms race that will lead to hasty decisions about whether an AI is safe. His argument seems to be that such a race is nearly inevitable, so the top priority should be ensuring that the better side wins. That could be a self-fulfilling prophecy.
Here’s a contrary opinion:
What US/China AI race folk sound like to me: There are superintelligent super technologically advanced aliens coming towards earth at .5 C. We don’t know anything about their values. The most important thing to do is make sure they land in the US before they land in China.
That reaction doesn’t seem quite right. It’s more like we’re facing waves of aliens heading our way, the first waves being not too technologically advanced. But I endorse the prediction that the differences between the US and China are small compared to the other uncertainties that we face.
Military Interest
The intelligence explosion will be more like running a war than launching a product.
It seems clear that within a matter of years, pre-superintelligence militaries would become hopelessly outclassed. … it seems likely the advantage conferred by superintelligence would be decisive enough even to preemptively take out an adversary’s nuclear deterrent.
I find it an insane proposition that the US government will let a random SF startup develop superintelligence. Imagine if we had developed atomic bombs by letting Uber just improvise.
I’ve been neglecting scenarios under which one or more militaries will take control of AI development, likely because I’ve been overly influenced by people on LessWrong who expect a brilliant insight to create an intelligence explosion that happens too fast for governments to react.
Aschenbrenner convinced me to expect a somewhat faster intelligence explosion than I previously expected. There’s some sense in which that moves me closer to Eliezer’s position. But Aschenbrenner and I both believe that the intelligence explosion will be a somewhat predictable result of some long-running trends.
So smart people in government are likely realizing now that the military implications deserve careful attention. If the US government is as competent now as it was in the early 1940s, then we’ll get something like the Manhattan Project. COVID has created some doubts as to whether people that competent are still in the government. But I suspect the military is more careful than most other parts of government to promote competent people. So I see at least a 50% chance that Aschenbrenner is correct here.
I’m not happy with military involvement. But if it’s going to happen, it seems better for it to happen now rather than later. A semi-prepared military is likely to make saner decisions than one that waits to prepare until the intelligence explosion.
It seems pretty clear: this should not be under the unilateral command of a random CEO. Indeed, in the private-labs-developing-superintelligence world, it’s quite plausible individual CEOs would have the power to literally coup the US government.
The world seems on track for a risky arms race between the free world and China. But I can imagine a sudden shift to a very different trajectory. All it would take is one fire alarm from an AI that’s slightly smarter than humans doing something malicious that causes significant alarm. Manifold takes that possibility somewhat seriously:
One key mistake by such an AI could be enough to unite the US and China against the common threat of rogue AI. I don’t expect AI at the slightly smarter than human stage to be saner and more rational than humans. It feels scary how much will depend on the details of mistakes made by such AIs.
How Close will the Arms Race be?
I feel more confused about the likely arms race than before.
The safety challenges of superintelligence would become extremely difficult to manage if you are in a neck-and-neck arms race. A 2 year vs. a 2 month lead could easily make all the difference. If we have only a 2 month lead, we have no margin at all for safety.
Aschenbrenner suggests treating the arms race as inevitable. Yet his analysis doesn’t suggest that the US will maintain much of a lead. He expects military-grade security to be implemented too late to keep the most important algorithmic advances out of CCP hands. I’ve been assuming a US hardware advantage will cause the US to win a race, but he expects that advantage to disappear. Even worse, the scenario that he predicts seems quite likely to push China to attack Taiwan at a key time, cutting off the main US supply of chips.
Would that mean China pulls ahead? Or that the US is compelled to bomb China’s chip factories? These scenarios seem beyond my ability to analyze.
Or if I’m right about China remaining behind in hardware, maybe the attack on Taiwan slows AI progress just as it reaches the intelligence explosion, buying some time at the critical juncture for adequate safety work.
Aschenbrenner doesn’t appear to have a lot of expertise in this area, but I’m unclear on how to find a better expert.
Political Options
Some hope for some sort of international treaty on safety. This seems fanciful to me. … How have those climate treaties gone?
The climate treaties haven’t mattered, because it turned out to be easier to rely on technological advances, plus the desire to avoid local air pollution. It feels like there was a fair amount of luck involved. A good treaty depends on a stronger consensus on near-term importance. Nuclear weapons treaties might provide a better example.
The United States must lead, and use that lead to enforce safety norms on the rest of the world. That’s the path we took with nukes, offering assistance on the peaceful uses of nuclear technology in exchange for an international nonproliferation regime (ultimately underwritten by American military power)—and it’s the only path that’s been shown to work.
This bears some resemblance to what’s needed. Does the US still have enough of a lead in military power for it to work as it worked after WWII? It seems hard to tell.
If some combination of governments is more concerned with existential risk and alignment, or with peace and cooperation, than Leopold expects, or there is better ability to work out a deal that will stick (38, 39 and 40) then picking up the phone and making a deal becomes a better option. The same goes if the other side remains asleep and doesn’t realize the implications. The entire thesis of The Project, or at least of this particular project, depends on the assumption that a deal is not possible except with overwhelming strength. That would not mean any of this is easy.
We’re not on track for a deal to be feasible, but we should very much keep our eyes open for circumstances under which it would become possible.
I was feeling fairly confused, before reading Situation Awareness, about the effects of trying to pause AI development. I feel even more confused now.
Aschenbrenner persuaded me that simple versions of a “pause” would only slow capabilities progress by about one third. The trends that he reports for algorithmic efficiency and unhobbling have a bigger impact on capabilities than I expected. The only pause proposals that are likely to effect those trends much are those that would decrease the available compute indefinitely. I want to emphasize that by decrease, I mean leading computing clusters would need to downgrade their chips yearly (monthly?). It would take unusual new evidence for those proposals to acquire the popularity that’s currently associated with a “pause” that merely limits AI training runs to 10^25 FLOPs or $100 million.
The recent price of NVIDIA stocks says quite clearly that we’re not on track for a pause that stops progress in AI capabilities.
Concluding Thoughts
Aschenbrenner has a more credible model than does Eliezer of an intelligence explosion. Don’t forget that all models are wrong, but some are useful. Look at the world through multiple models, and don’t get overconfident about your ability to pick the best model.
His “optimistic” perspective has increased my gut-level sense of urgency and led me to revise my probability of an existential catastrophe from 12% to 15%, primarily due to the increased likelihood of a closely-fought arms race.
He’s overconfident, but well over half right.
“Situational Awareness” contains more valuable insights than I can summarize in one post. It is important reading for anyone interested in the future of AI development and its global implications.
P.S. See Michaël Trazzi’s amusing summary of Aschenbrenner’s background.